Hee Min Choi* † · Hyoa Kang* · Dokwan Oh
Abstract
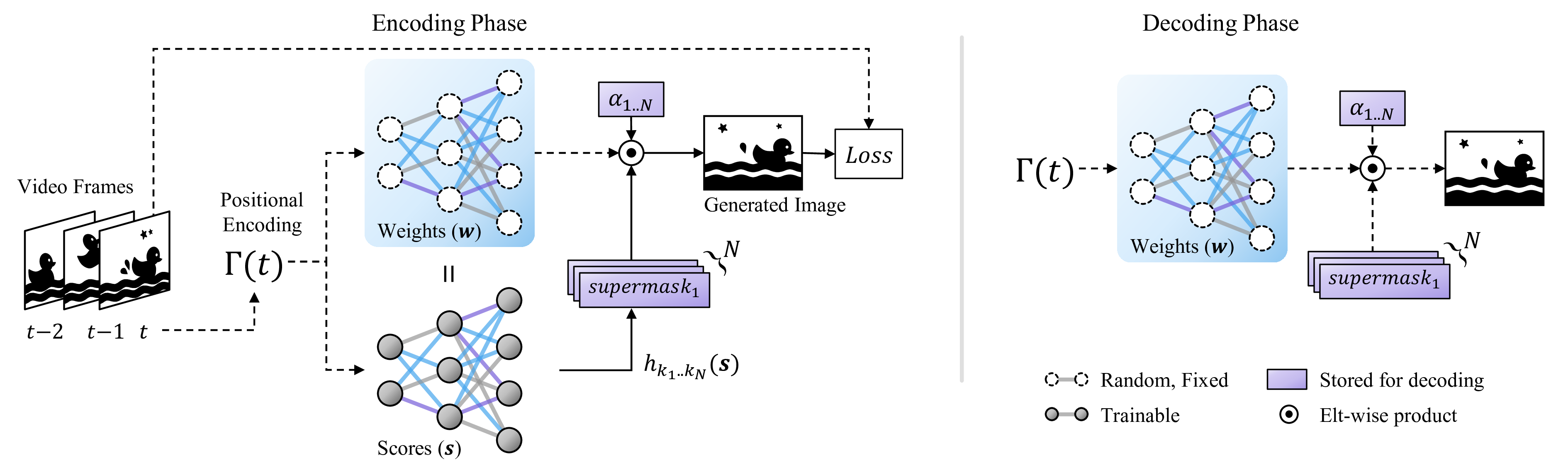
Compact representation of multimedia signals using implicit neural representations (INRs) has advanced significantly over the past few years, and recent works address their applications to video. Existing studies on video INR have focused on network architecture design as all video information is contained within network parameters. Here, we propose a new paradigm in efficient INR for videos based on the idea of strong lottery ticket (SLT) hypothesis (Zhou et al., 2019), which demonstrates the possibility of finding an accurate subnetwork mask, called supermask, for a randomly initialized classification network without weight training. Specifically, we train multiple supermasks with a hierarchical structure for a randomly initialized image-wise video representation model without weight updates. Different from a previous approach employing hierarchical supermasks (Okoshi et al., 2022), a trainable scale parameter for each mask is used instead of multiplying by the same fixed scale for all levels. This simple modification widens the parameter search space to sufficiently explore various sparsity patterns, leading the proposed algorithm to find stronger subnetworks. Moreover, extensive experiments on popular UVG benchmark show that random subnetworks obtained from our framework achieve higher reconstruction and visual quality than fully trained models with similar encoding sizes. Our study is the first to demonstrate the existence of SLTs in video INR models and propose an efficient method for finding them.
Architecture
Decoded Images
Proposed (learned scales) vs. Trained Dense
| Ground Truth | Proposed (learned scales), BPP=0.060 | Trained Dense, BPP=0.064 |
 |
 |
 |
 |
 |
 |
Proposed (learned scales) vs. Trained Sparse
| Ground Truth | Proposed (learned scales), BPP=0.060 | Trained Sparse, BPP=0.076 |
 |
 |
 |
 |
 |
 |
Proposed (learned scales) vs. Proposed (fixed scales)
| Ground Truth | Proposed (learned scales), BPP=0.060 | Proposed (fixed scales), BPP=0.060 |
 |
 |
 |
 |
 |
 |
FLIP Visualization
We further provide FLIP maps for the decoded images. FLIP generates a map of approximating errors recognized by humans when alternating between two images. In FLIP maps, bright color corresponds to large error and dark to small error, and smaller FLIP value is better. We find that at low BPP settings (BPP < 0.1), the proposed method better encodes small objects in large area having repeated patterns compared with three baseline methods.
Proposed (learned scales) vs. Trained Dense
Bosphorus
| Proposed (learned scales), BPP=0.060 | Trained Dense, BPP=0.064 | |
| FLIP |  FLIP=0.1258 |
 FLIP=0.1613 |
| Decoded Image |
|
|
HoneyBee
| Proposed (learned scales), BPP=0.060 | Trained Dense, BPP=0.064 | |
| FLIP | 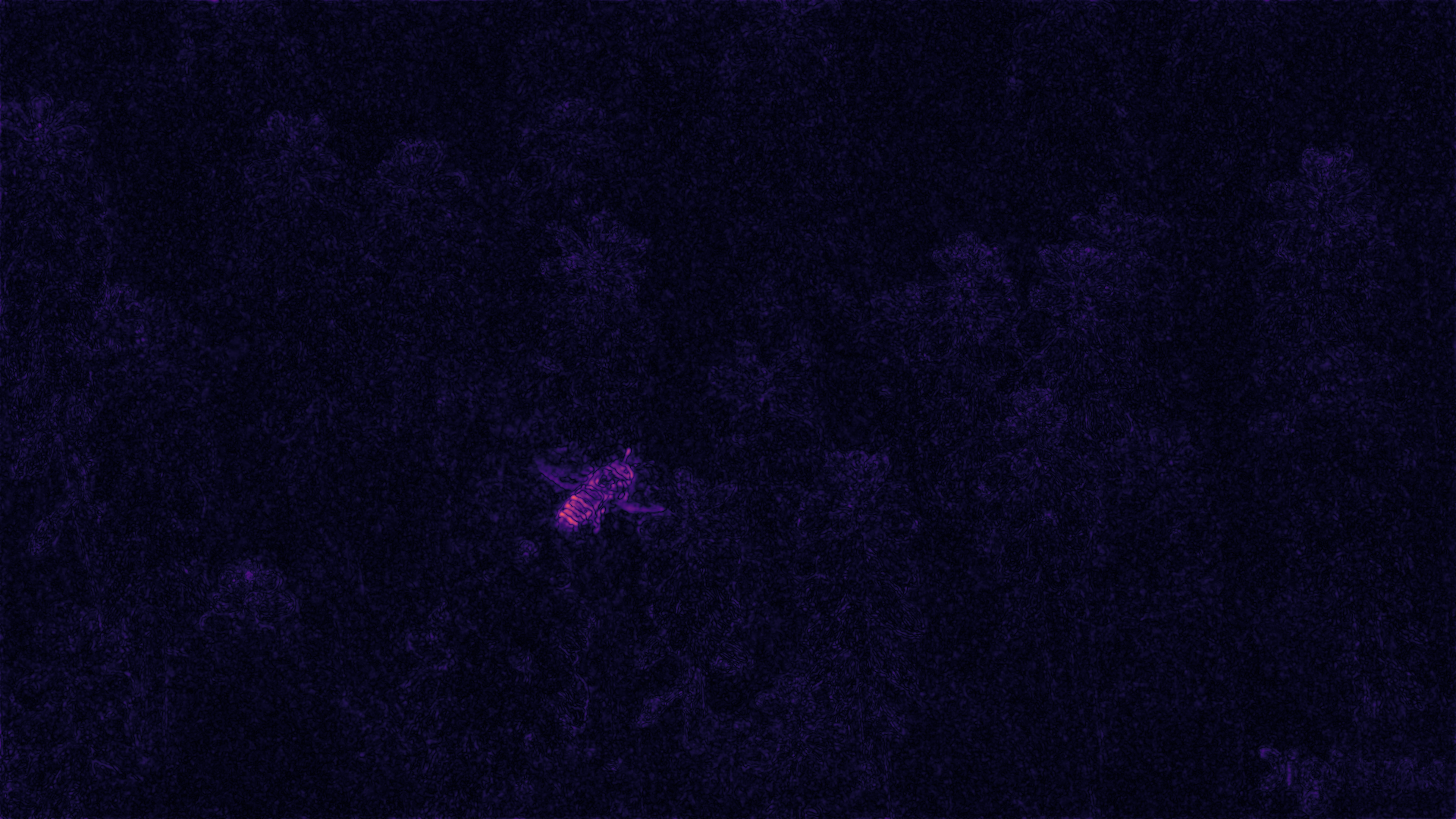 FLIP=0.0532 |
 FLIP=0.0534 |
| Decoded Image |
|
|
Proposed (learned scales) vs. Trained Sparse
Beauty
| Proposed (learned scales), BPP=0.060 | Trained Sparse, BPP=0.076 | |
| FLIP |  FLIP=0.0702 |
 FLIP=0.0768 |
| Decoded Image |
|
|
YachtRide
| Proposed (learned scales), BPP=0.060 | Trained Sparse, BPP=0.076 | |
| FLIP |  FLIP=0.1258 |
 FLIP=0.1499 |
| Decoded Image |
|
|
Proposed (learned scales) vs. Proposed (fixed scales)
Jockey
| Proposed (learned scales), BPP=0.060 | Proposed (fixed scales), BPP=0.060 | |
| FLIP |  FLIP=0.1401 |
 FLIP=0.1466 |
| Decoded Image |
|
|
ReadySteadyGo
| Proposed (learned scales), BPP=0.060 | Proposed (fixed scales), BPP=0.060 | |
| FLIP |  FLIP=0.1761 |
 FLIP=0.1932 |
| Decoded Image |
|
|
Citation
@inproceedings{choi2023inrslt,
author = {Choi, Hee Min and Kang, Hyoa and Oh, Dokwan},
title = {Is Overfitting Necessary for Implicit Video Representation?},
booktitle = {Proceedings of the 40th International Conference on Machine Learning},
year = {2023}
}